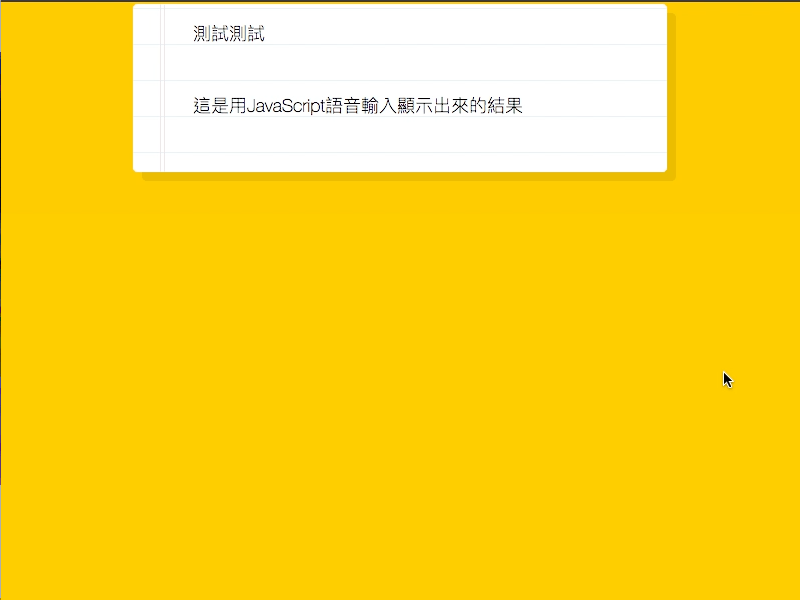
主題
利用SpeechRecognition來做語音識別,
並透過interimResults來輸出識別的結果。
步驟
Step1. 啟動Local Server
這個練習需要使用到local server,
如果你已經有一個可在本機run起來的server可以直接使用,
或在這層資料夾底下運行npm install來安裝browser-sync,
安裝完成後可以透過指令npm start來啟動localserver(預設port3000),
npm指令需要下載node.js來使用
Step2. 將SpeechRecognition建立起來
1 | // 將全域環境中的SpeechRecognition指好(依據不同瀏覽器) |
參閱:MDN-SpeechRecognition.interimResults
Step3. 把輸出區域準備好
1 | // 建立一個p元素在html設定好的文字區中 |
Step4. 對識別系統做監聽
識別回傳的資料是NodeList,所以要用map操作得先轉array1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24// 監聽識別回傳
recognition.addEventListener('result', e => {
// 將回傳資料先轉為array來操作
const transcript = Array.from(e.results)
// 透過map取得回傳陣列中的第0筆
.map(result => result[0])
// 在取得第0筆中的transcript
.map(result => result.transcript)
// 用join把連結符號消掉
.join('')
// 把回傳內容塞到p元素中
p.textContent = transcript;
// 如果回傳內容已經結束(一段話的結尾)在建立一個新的p元素來放下一段文字
if (e.results[0].isFinal) {
p = document.createElement('p');
words.appendChild(p);
}
})
// 監聽如果語音識別結束,則在開啟一次新的識別
recognition.addEventListener('end', recognition.start);
// 開始識別
recognition.start();
其他
在測試的過程中,不知道是我發音的問題還是怎麼回事,
我在說出localhost的過程中居然被識別成Tokyo HotXDDDD